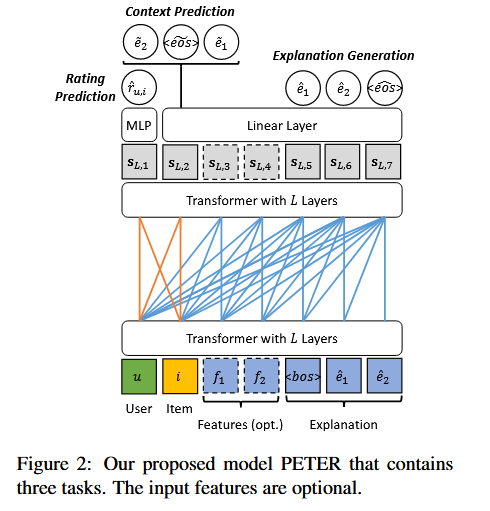
用户模拟器在会话推荐中的使用
用户模拟器在会话推荐中的使用
PeterRethinking the Evaluation for Conversational Recommendation in the Era of Large Language Models
目前的CRS可以被分为两种类型: 基于属性的CRS,基于NLP的CRS 前者侧重于通过尽可能少的交互了解用户的实时偏好来实现成功的推荐;后者侧重于为用户提供更理想的对话体验。
Challenge: 在基于属性的 CRS 中,Simulator的响应基于固定模板,忽略了对话的流程; 基于 NLP 的 CRS 虽然考虑了对话的流程,但评估是基于固定对话的,这可能会忽略对话推荐的交互性。
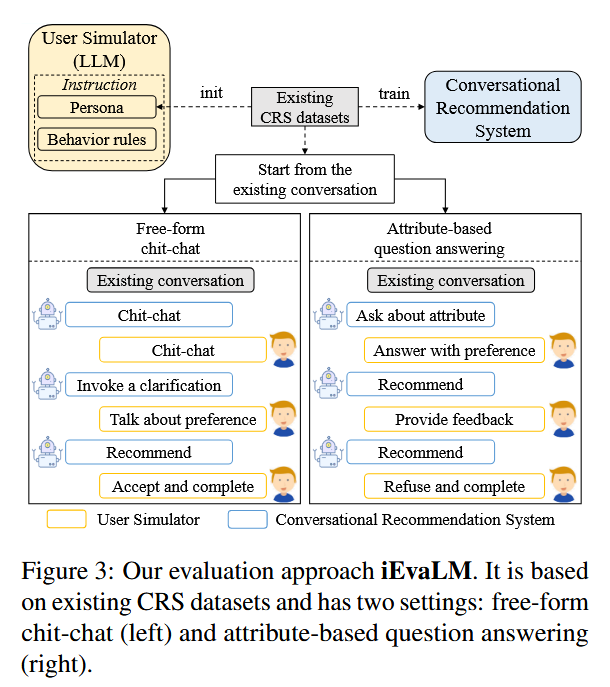
现有的用户模拟方法大多仅限于预定义的对话流或基于模板的话术,为了构建一个更灵活的User Simulator对CRS进行交互式评估, 本篇工作使用基于LLM设计了User Simulator,并考虑了两种类型的交互:基于属性的问答和自由形式的闲聊。
论文中通过实验论证指出,为什么在仅基于对话历史的情况下使用ChatGPT作为Recommender会出现准确率不高的情况:(1)缺乏明确的用户偏好:对话历史如果只有非常短的轮次,CRS 可能无法收集足够的证据来准确推断用户意图。(2) 缺乏主动澄清:在现实世界的场景中,CRS 会在需要时提出主动澄清,而现有的评估协议并不支持这一点
How Reliable is Your Simulator? Analysis on the Limitations of Current LLM-based User Simulators for Conversational Recommendation
这篇工作主要用于指出使用llm-based simulator对CRS进行交互性评估中存在的一些问题,(1)数据泄露: 在Recommender与Simulator发生交互的过程中可能会泄露target items (2) CRS给出的建议更依赖于原始对话历史,而非Simulator的响应 (3)通过单提示模板控制用户模拟器的输出被证明是具有挑战性的
改进方案:(1)确保在对话过程中,模拟器只知道target item的属性信息。即在成功进行推荐之前,Simulator不知道target item的标题。(2)多提示策略: 根据 CRS 的意图(闲聊,推荐,问询),分别采取以下行动:• 闲聊: 根据当前主题结合当前偏好生成响应流。• 询问: 根据实时偏好回答 CRS 的问题。• 推荐: 检查推荐项目是否与其目标项目一致,并相应地提供正面或负面反馈。
Search-Based Interaction For Conversation Recommendation via Generative Reward Model Based Simulated User
前面交代的工作主要使用Simulator对CRS进行评估,并且以往关于Simulator的构建往往依赖目标商品项的属性来模拟用户偏好,如何在没有ground-truth labels的情况下开发一款模拟器是显著的挑战。
本工作使用一个无标记的Simulator(GRSU)来捕获实时用户偏好。GRSU可以通过两个受生成式奖励模型启发的动作来提供反馈:生成式项目评分(粗粒度反馈)和基于属性的项目批判(细粒度反馈)。这两个动作被统一到指令格式中,从而可以通过指令调整来开发统一的模拟用户。

Expectation Confirmation Preference Optimization for Multi-Turn Conversational Recommendation Agent
本工作引入了一种多轮次偏好优化范式ECPO,它利用期望确认理论来明确模拟用户满意度在整个多轮次对话中的演变,从而揭示不满意的根本原因。这些原因可用于支持对不满意响应的定向优化,从而实现轮次级首选项优化。
对话推荐是一个多轮对话任务,用户偏好在每个对话回合都会发生变化,目前已有的多轮偏好优化方法只是平等的对待每个轮次,无法捕获轮次级偏好关系。基于树状推理的轮次级偏好优化存在以下问题:(1)需要对每个中间过程的多个候选回答进行采样,并模拟整个对话流程,导致大量的开销 (2)在多轮对话推荐任务中,LLM难以通过子采样产生有效的正样本输出 (3)评估中间轮次的偏好依赖于模拟环境,起随机性可能在偏好关系中引入额外的噪声
该工作的核心在于明确模拟用户的满意度在多轮次对话场景中的演变,并揭示“不满意”的原因。这里的满意度是指用户的期望与感知的结果之间的差异比较。作者提出了一个ECPO优化方案,主要有三个核心步骤组成:(1)Forward Expectation Confirmation:,识别不满意的回答并揭示其根本原因;(2)Backward Expectation Derivation: 根据这些原因重写不满意的回答;(3)Preference Optimization: 使用原始和重写的响应进行用户偏好优化。