写在前面:前段时间把b站上北大肖老师的区块链课程速通了一遍,这里引一下csdn上的优质课程笔记,便于个人后续温习。博客链接:https://blog.csdn.net/qq_40378034/category_11862943.html课程链接:https://www.bilibili.com/video/BV1Vt411X7JF/
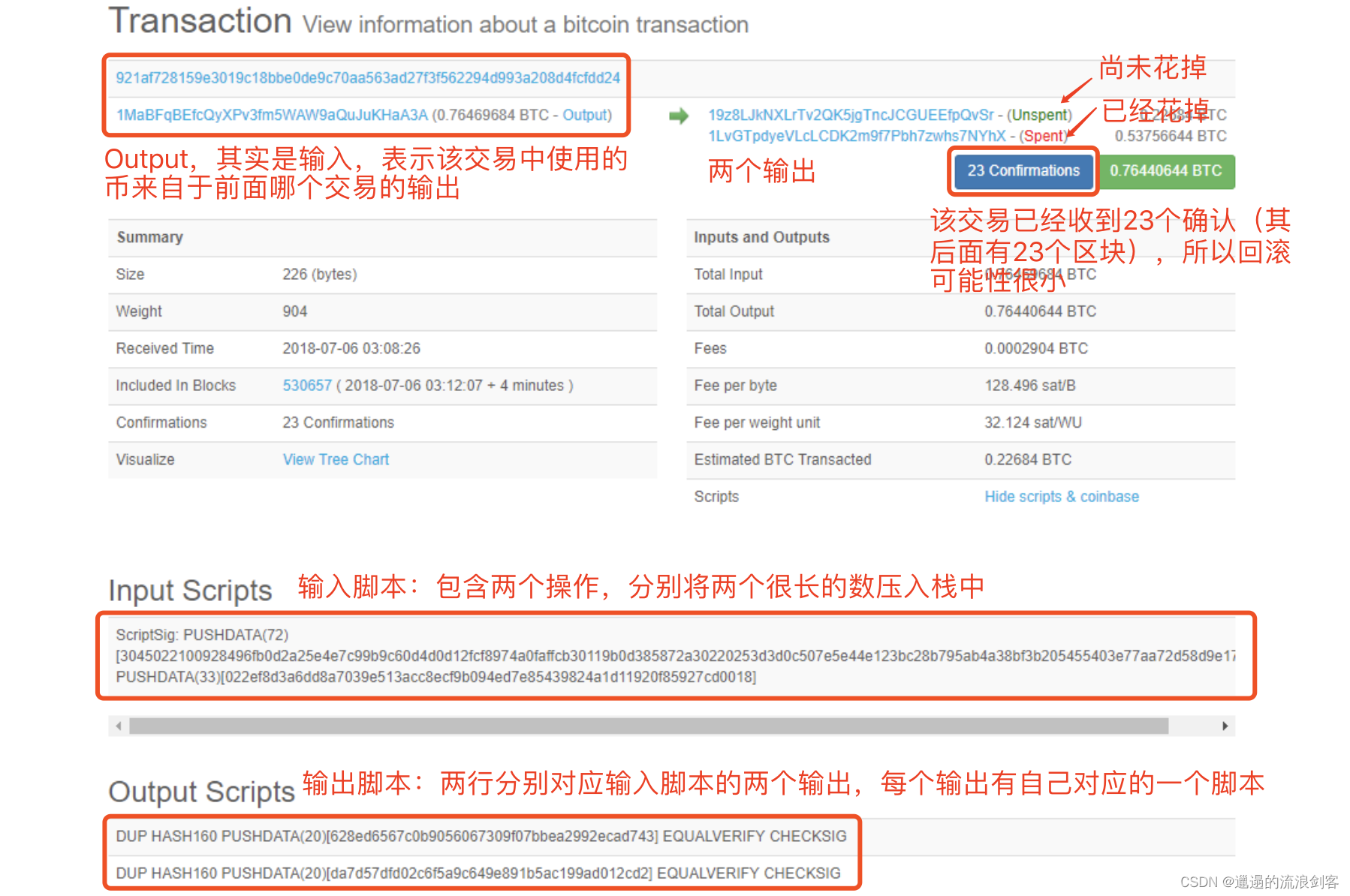
5、BTC-网络用户将交易发布到比特币网络上,节点收到交易后打包到区块中,然后将区块发布到比特币网络上,那么新发布的交易和区块在比特币网络上是如何传播的呢?
比特币工作于网络应用层,其底层(网络层)是一个P2P Overlay Network(P2P覆盖网络)
应用层:Bitcoin Blockchain
网络层:P2P Overlay Network
比特币系统中所有节点都是对等的,不像一些其他网络存在超级节点(super node或master node)。要加入网络,至少需要知道一个种子节点(seed node),通过种子节点告知自己它所知道的节点。节点之间的通信采用了TCP协议,便于穿透防火墙。当节点离开时,只需要自行退出即可,其他节点在一定时 ...

写在前面:前段时间把b站上北大肖老师的区块链课程速通了一遍,这里引一下csdn上的优质课程笔记,便于个人后续温习。博客链接:https://blog.csdn.net/qq_40378034/category_11862943.html课程链接:https://www.bilibili.com/video/BV1Vt411X7JF/
10、ETH-The DAO1)、The DAO比特币实现了去中心化的货币,以太坊实现了去中心化的合约,有人想既然去中心化这么好,为什么不把所有的东西都改成去中心化呢?有人提出口号:let’s decentralize everything。DAO(Decentralized Autonomous Organization,去中心化的自治组织)就是在这个背景下产生的。传统社会中,组织都是建立在某种法律文件基础上的,比如说可以有个章程规范组织的行为,有时候还可能到政府登记注册。那DAO就是把组织的规章制度写在代码里,通过区块链的共识协议来维护这种规章制度的正常执行
在2016年5月,出现了一个致力于众筹投资的DAO,它的名字为The DAO。DAO是一个通用 ...
写在前面:前段时间把b站上北大肖老师的区块链课程速通了一遍,这里引一下csdn上的优质课程笔记,便于个人后续温习。博客链接:https://blog.csdn.net/qq_40378034/category_11862943.html课程链接:https://www.bilibili.com/video/BV1Vt411X7JF/
5、ETH-GHOST以太坊把出块时间降到了十几秒,这对于提高系统的throughput(吞吐量)和降低反应时间来说都是很有帮助的,跟比特币的10分钟的出块时间相比,以太坊的出块速度相当于提高到了40倍
但是这样大幅度降低出块时间之后也带来一些新的问题,比特币和以太坊都是运行在应用层的共识协议,底层是一个P2P的Overlay Network,这个Overlay Network本身传输的时间是比较长的,因为它的拓扑协议做flooding的时候没有考虑实际的拓扑结构,就带来一个问题,发布一个区块的时候,这个区块在网络上传到其他节点可能需要十几秒的时间
对于比特币来说,10分钟的出块时间相当于600秒,足够让新发布的区块传播到网上的其他节点,即使这样,因为挖矿 ...
写在前面:目前主流的LLM post-training框架主要有trl, OpenRLHF, verl。后两者集成度较高,适合对LLM零代码训练,而trl灵活性较强,这里主要对GRPO Trainer的训练流程进行梳理
GRPOTrainer类它继承了transformers.Trainer,并重写或拓展了若干方法,包括:init作用:初始化模型、参考模型(ref_model)、奖励模型(reward_funcs)等,并作一些超参数设置(如 num_generations, beta 等)。
model: 加载策略模型, 可以是字符串(模型ID或路径)或预训练模型对象。仅支持因果语言模型
reward_funcs: 加载奖励函数,可以是预训练模型(仅支持SequenceClassification模型);用户自定义Python函数;或者是一个列表,意味着多种奖励函数一起用
args: GRPOConfig对象,包含训练的所有参数
train_dataset: 训练数据集,必须包含名为’prompt’的列,可以是Dataset或IterableDataset
eval_dataset: ...
人工智能
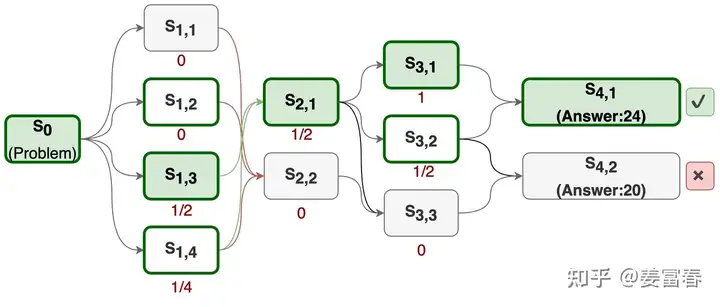
未读ORM 和 PRMORM:结果奖励模型,是不管推理有多少步,对完整的生成结果进行一次打分,是一个反馈更稀疏的奖励模型PRM:过程奖励模型,是在生成过程中,分步骤,对每一步进行打分,是更细粒度的奖励模型
使用PRM可以在post-training和inference两个阶段提升模型的推理性能:
Post-Training阶段:在偏好对齐阶段,通过在RL过程中增加PRM,对采样的结果按步骤输出奖励值,为模型提供更精细的监督信号,来指导策略模型优化,提升模型按步推理的能力
Inference阶段:对于一个训练好的PRM,可以在inference阶段筛选优质生成结果。
MCTS 蒙特卡洛树搜索MCTS是强化学习领域提出的方法,通过采样方式预估当前动作或状态的价值。具体操作步骤:使用已有的策略与环境做仿真交互,进行多次rollout采样,最终构成了一个从当前节点出发的一颗Tree(每个rollout表示从当前节点到最终结束状态的多次与环境仿真交互的过程)。这颗Tree的所有叶子节点都是结束状态,结束状态是可以通过定义规则进行量化收益的。当Tree的叶子结点有了奖励值,就可通过反向传播,计算每 ...
1. PPO算法 $ L_{PPO} = \sum_{(s_t,a_t)}\frac{\pi_\theta(a_t|s_t)}{\pi_{ref}(a_t|s_t)}A(s_t,a_t) - \beta KL(\pi_\theta, \pi_{ref}) $
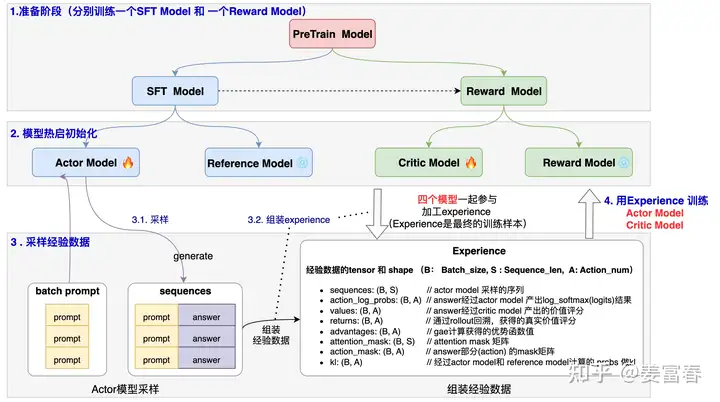
PPO的训练步骤如下:(1)收集人类反馈,人工标注数据 (2)训练奖励模型 (3)采用PPO强化学习,优化策略
在LLM上使用PPO算法进行post-training时,主要涉及4个model:
Actor Model: 是我们要优化学习的策略模型,同时用于做数据采样,用SFT Model热启
Reference Model: 是为了控制Actor模型学习的分布与原始模型的分布相差不会太远的参考模型,通过loss中增加KL项,来达到这个效果。训练过程中该模型不更新
Critic Model:是对每个状态做打分的价值模型,衡量当前token到生成结束的整体价值打分,一般可用Reward Model热启
Reward Model:对整个生成的结果打分,是事先训练好的Reward Model。训练过程中该模型不更新
2. DPO算 ...
生活日常
未读下载安装# 1、下载最新部署包curl -s https://api.github.com/repos/syncthing/syncthing/releases/latest | grep browser_download_url | grep linux-amd64 | cut -d '"' -f 4 | wget -qi -# 2、解压并安装tar -xvf syncthing-linux-amd64-v1.28.1.tar.gzmv syncthing-linux-amd64-v1.28.1/syncthing /usr/bin/# 3、启动并且测试syncthing
开机自启如果要立刻启动syncthing,直接使用命令 syncthing 即可,但这样运行十分不优雅,因此可以使用systemd配置开机自启。创建一个新的 systemd 服务文件:sudo nano /etc/systemd/system/syncthing.service[Unit]Description=Syncthing - Open Source Continuous Fi ...
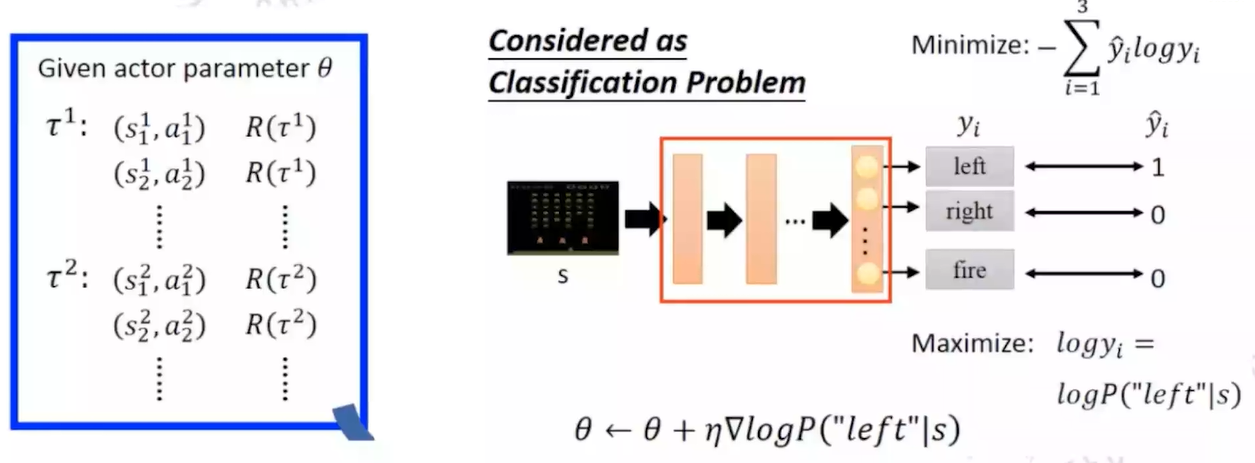
写在前面:前面所提到的Q-value Based方法无法解决连续动作空间场景下的优化问题,因为Q-learning的策略是从多个离散动作中贪婪地选择最大Q值,在连续空间中,无法枚举所有动作。为此,本节讲述一种直接面向策略的优化方法:Policy Gradient
1. Policy Gradient训练目标: $ \pi_\theta(s,a)=P[a|s,\theta] $Ques: 什么样的策略算是好的策略,如何进行梯度更新Ans:think $ \theta $ 会影响策略 $ \pi $ , $ \pi $ 会影响episode采样路径 $ \tau={s_1,a_1,r_1,s_2,a_2,r_2,…,s_T,a_T,r_T} $ ,根据 $ \tau $ , 我们可以算出 $ R(\tau)=\sum_{n=1}^N r_n $ ,我们希望采样路径的 $ R(\tau) $ 尽可能的大method用采样路径的平均收益来评价一个 $ \theta $ 的好坏 $ \bar R_\theta = \sum_{\tau} R(\tau) \cdot P(\tau|\theta) ...
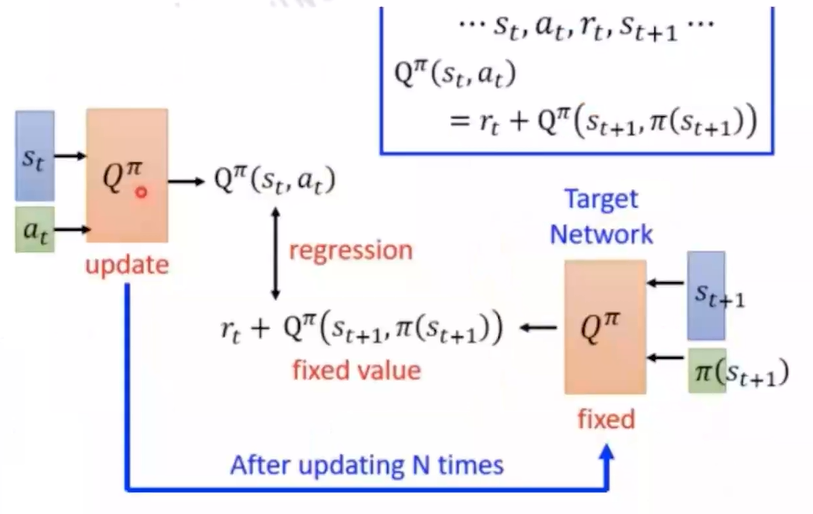
写在前面:前面讲解了在On-Policy和Off-Policy环境下如何进行策略提升的几种常用方法,但是在实际应用场景中,state的数量可能是非常庞大的,为了存储每个state-action pair所需要的lookup-table所需要的空间会很庞大,无法通过遍历的方式去evaluate每个state-action pair。这就需要我们考虑如何对Q,V进行建模,通过函数逼近的方法估计连续空间下的state value
1. Value ApproximationTarget: 寻找到合适的参数w使得mse loss尽可能的小 $ J(w)=E_\pi[(v_\pi(S)-\hat{v}(S,w))^2] $通过梯度下降来更新w: $ \Delta w=-\frac{1}{2}\alpha \nabla_w J(w)=\alpha(v_\pi(S)-\hat{v}(S,w))\nabla_w\hat{v}(S_t,w) $
使用特征向量表示state $ x(S)=(x_1(S)…x_n(S)) $ $ \hat{v}(S_t,w) $ 可以通过线性加权得到,即 $ \h ...
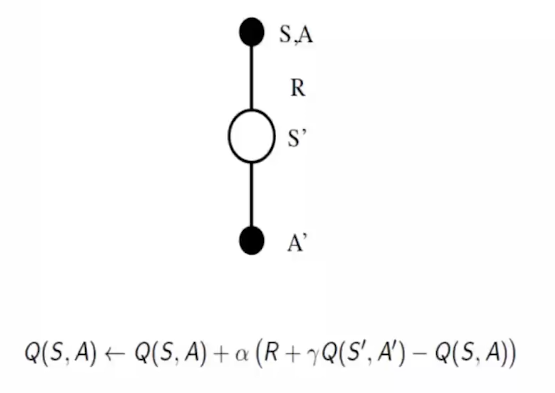
写在前面:系列二中提及的MC/TD方法都是在已知策略 $ \pi $ 的前提下,估计每个状态的期望回报。前者是等到整个回合结束利用完整回报 $ G_t $ 来更新价值函数,后者利用一步预测和当前奖励动态更新价值函数。可以看到的是,这些方法知识学习了价值函数,并没有改变策略。在这一节,我们主要介绍一些常用的策略优化方法。
1. Epsilon Greedy在Model-based Control中,我们基于MDP Transition采用贪心策略进行policy improvement: $ \pi’(s)=argmax_{a \in A}R_s^a + P_{ss’}^aV(s’) $在Model-free背景下,由于缺失MDP Transition,往往采用对行为价值函数Q(s,a)进行建模: $ \pi’(s)=argmax_{a \in A}Q(s,a) $这里介绍一个常用的贪心策略Epsilon Greedy:
\pi(a|s) =
\begin{cases}
\frac{\epsilon}{m} + 1 - \epsilon & \text{if } a = \arg\ ...

