打算花点时间看看在peft库中lora是怎么注入base model的,这里简单总结下:
首先写个测试程序:
import torchfrom peft import LoraModel, LoraConfigfrom transformers import AutoModelForCausalLM, AutoTokenizermodel = AutoModelForCausalLM.from_pretrained('meta-llama/Llama-2-7b-hf', torch_dtype=torch.float16, device_map="cuda")tokenizer = AutoTokenizer.from_pretrained('meta-llama/Llama-2-7b-hf')tokenizer.pad_token = tokenizer.eos_tokenlora_config = LoraConfig( r=32, lora_alpha=16, target_modules=[" ...
写在前面: Prediction任务是用来在给定策略 $ \pi $ 的前提下,基于价值函数和奖励函数来评估该策略的好坏。Control任务用来对策略进行提升和改进。根据是否已知状态转移矩阵(MDP transition)分为Model-Based Prediction和Model-free Prediction
Model-Based Prediction&Control1. Policy Iteration策略迭代(Policy Iteration)是一种用于求解马尔可夫决策过程(MDP)的动态规划算法。它主要用于寻找最优策略,即在给定MDP的情况下,使得累计奖励最大的策略。step: (1)策略评估(Policy Evaluation) Prediction Phase在当前策略 $ \pi $ 下,计算所有状态s的状态函数 $ V^{\pi}(s) $ , $ V^{\pi}(s)=\sum_{a}\pi(a|s)[R_s^a +\gamma \sum_{s’}P_{ss’}^a V^\pi(s’)] $(2) 策略改进(Policy Improvement) Con ...

人工智能
未读三要素:rewards, actions, states
马尔可夫奖励过程:马尔可夫奖励过程可以表示为 $ $ ,其中:
$ S $ 为状态集合;
$ P $ 为状态转移矩阵, $ P_{ss’}=P[S_{t+1}=s’|S_t=s] $ ;
$ R $ 为奖励函数, $ R_s=E[R_{t+1}|S_t=s] $ ;
$ \gamma $ 为折扣因子, $ \gamma \in [0,1] $ 。
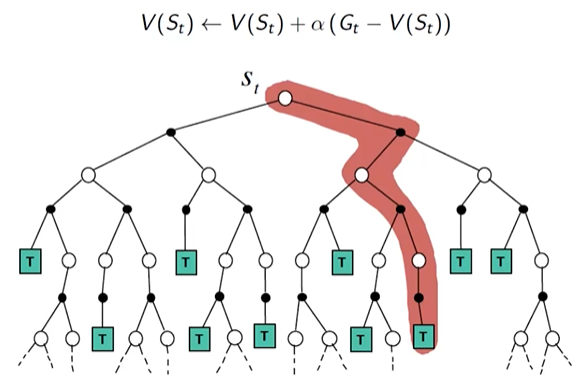
总折扣奖励:回报(Return) $ G_t $ 表示从时刻 $ t $ 开始的总折扣奖励:
G_t=R_{t+1}+\gamma R_{t+2}+...=\sum_{k=0}^\infty \gamma^k R_{t+k+1}
状态价值函数: $ v(s)=E[G_t|S_t=s] $
行为价值函数: $ q(s,a)=E[G_t|S_t=s,A_t=a] $
Bellman 方程:Bellman 方程表示状态价值函数的递归形式:
v(s)=E[G_t|S_t=s]=E[R_{t+1}+\gamma R_{t+2}+...|S_t=s]=E[R_{ ...
Web3
未读安装Remix-ide先排个雷,目前官方提供的remix-ide desktop版能安装,但是跑不起来,我在github release列表下了latest version,启动后就是漫长的白屏,网上给的解释是需要修改代理ping通github,但是我这边是能ping通的,多次尝试无果后我选择使用Remix-Ethereum IDE + 本地 remixd。remixd是Remix IDE提供的一个辅助工具,主要用于 Solidity 智能合约开发时,让本地文件系统和 Remix Web IDE 之间建立连接。安装方式:npm install -g @remix-project/remixd启动命令:remixd -s ./ —remix-ide https://remix.ethereum.org
vscode + solc需要在vscode中安装solidity插件,另外也可安装remix-light插件用于轻量化编译、部署。使用solidity插件对sol编译的方式是右键选择Solidity:Compile Contract。如果编译器版本不匹配的话,solidity插件支持三种 ...
区块链与加密货币入门指南基础篇:区块链与加密货币基础学习目标
理解区块链基本原理
掌握加密货币基础知识
了解DeFi生态系统
尝试链上交互
核心学习资源1. 入门
视频教程: 3Blue1Brown的”比特币和区块链是如何工作的” - 通过可视化方式解释区块链的基本原理
在线课程: Coursera - 区块链基础知识 & PKU学生区块链中心WEB3新人公开课
书籍: 《精通比特币》(Mastering Bitcoin) - Andreas Antonopoulos著
指南: 区块链技术指南 - 完整的中文区块链入门资料
DeFi 工具扫盲
2. 白皮书
官方文档: 比特币白皮书 - 了解比特币的设计理念
视频:Whiteboard Crypto - 简化的加密货币教学
4. 实践项目
创建和管理加密钱包
OKX 钱包 / Metamask / …
学习私钥管理和安全
在测试网络获取测试代币
体验基本的区块链交互
在测试网络上发送交易
使用区块浏览器如Etherscan查看交易
参与简单的代币交换(使用Uniswap测试网)
进阶篇:智能合约与DeFi核心 ...
人工智能
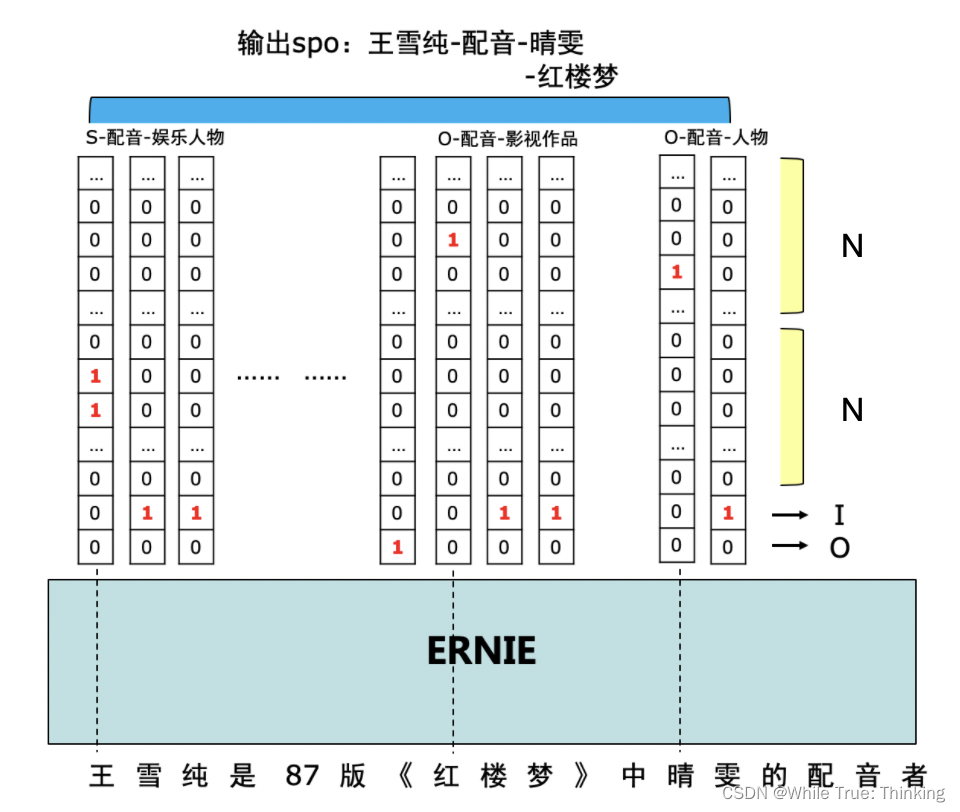
未读BIO标记法B-(Begin):表示一个实体的开始(首个 token)。
I-(Inside):表示实体的内部(除首个 token 以外的部分)。
O-(Outside):表示非实体的 token。
例如:**”Apple Inc. is based in California.”
BIO 标注:
Token
BIO 标签
Apple
B-ORG
Inc.
I-ORG
is
O
based
O
in
O
California
B-LOC
.
O
常见的实体类别
实体类别
含义
PER (Person)
人名(例如:Elon Musk, Bill Gates)
ORG (Organization)
组织名(例如:Apple, Google, NASA)
LOC (Location)
地名(例如:California, Beijing, Paris)
MISC (Miscellaneous)
其他(例如:品牌名、事件名等)
在 NER 任务 中,BIO 标签常作为序列标注模型(如 BiLSTM-CRF、Tr ...
人工智能
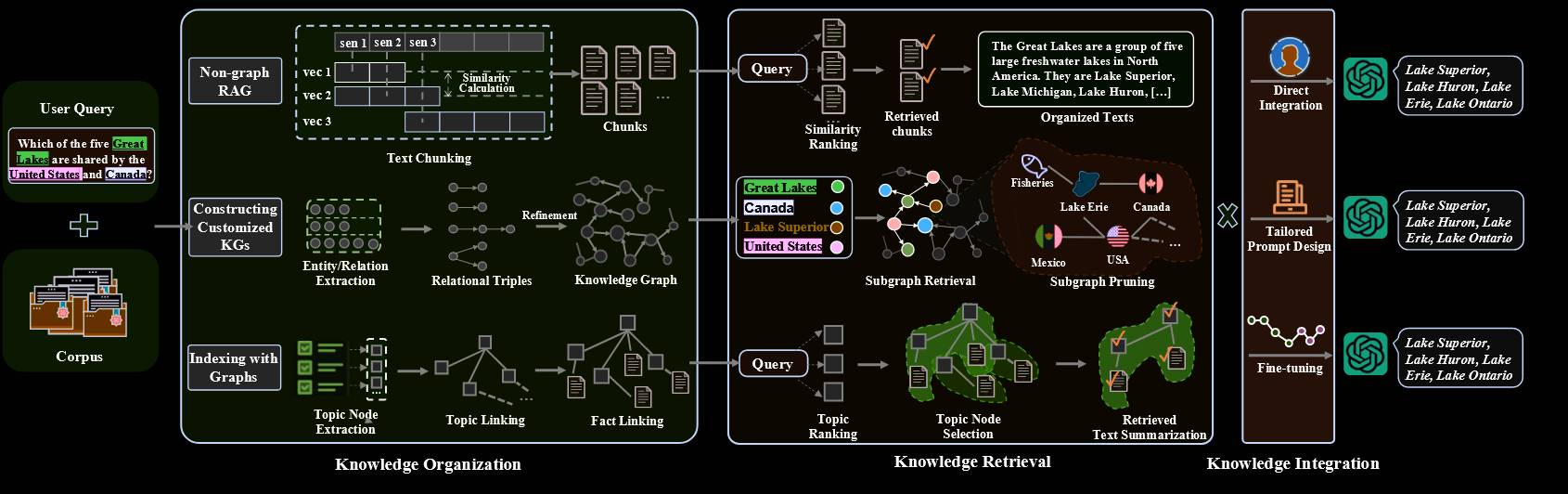
未读Sec.1 传统RAG系统面临的挑战复杂的查询理解:传统的 RAG 方法依赖于简单的关键字匹配和向量相似性技术,不足以捕捉准确和全面所需的深层语义细微差别和多步骤推理过程。例如,当询问概念 A 和概念 D 之间的联系时,这些系统通常只检索直接相关的信息,而错过了像 B 和 C 这样可以弥合关系的关键中间概念。这种狭窄的检索范围限制了 RAG 的能力,使其无法进行广泛的上下文理解和复杂的推理
集成来自分布式源的领域知识:检索到的知识通常是扁平的、广泛的和错综复杂的,而领域概念通常分散在多个文档中,不同概念之间没有明确的层次结构关系。尽管 RAG 系统试图通过将文档划分为较小的块以实现有效和高效的索引来管理这种复杂性,但这种方法无意中牺牲了关键的上下文信息,严重损害了检索准确性和上下文理解。这种限制阻碍了在相关知识点之间建立强大联系的能力,导致理解碎片化,并降低利用特定领域专业知识的效率。
LLM的固有约束:受到其固定上下文窗口的限制,LLM无法完全捕获复杂文档中的长距离依赖关系。在专业领域中,在广泛的知识背景下保持连贯性的挑战变得越来越棘手,因为关键信息可能会在上下文窗口截断期间丢失。
...
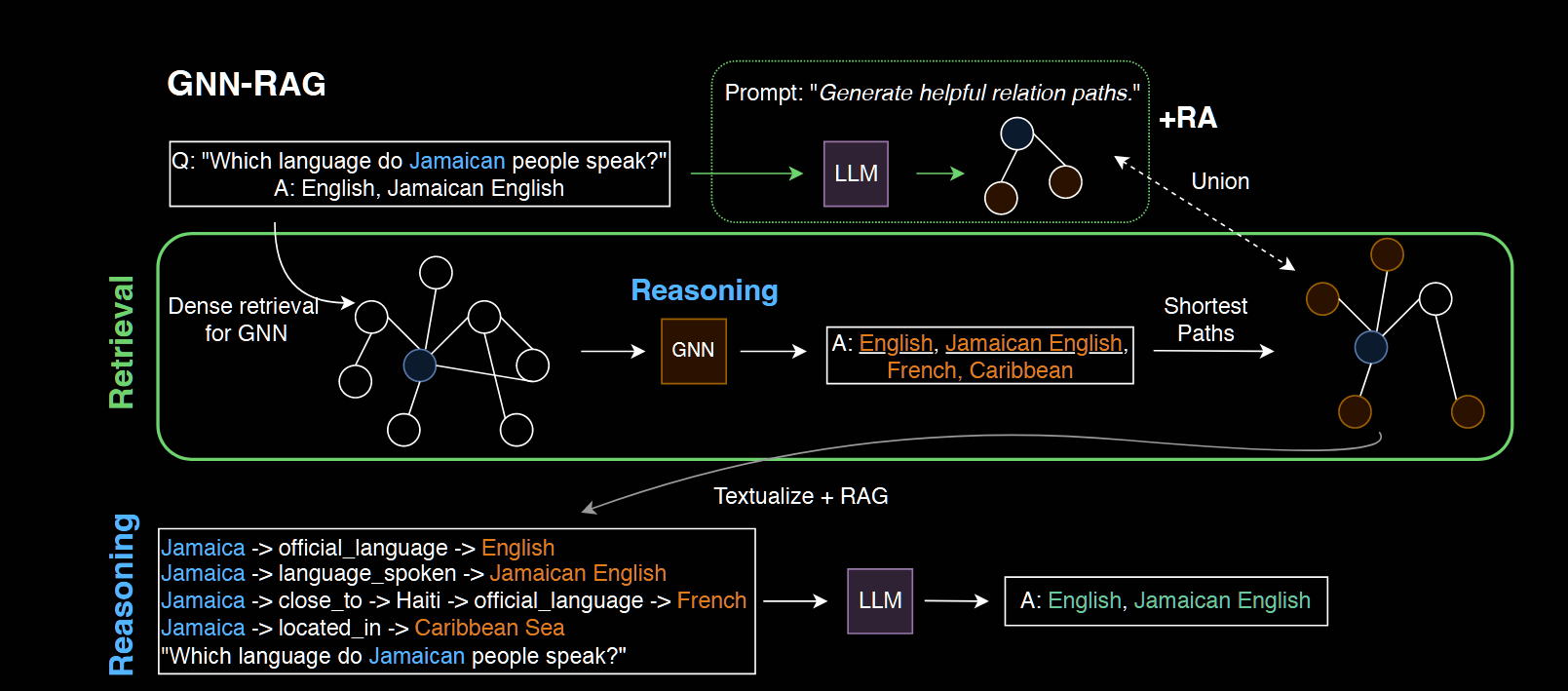
1.GNN-RAG: Graph Neural Retrieval for Large Language Model Reasoning
开源代码:https://github.com/cmavro/GNN-RAG
Motivation: 将GNN的推理能力和LLM的语言理解能力相结合用于知识图谱问答
Methodology:首先,GNN 对密集的 KG 子图进行推理,以检索给定问题的答案候选者。其次,提取 KG 中连接问题实体和答案候选项的最短路径以表示 KG 推理路径。提取的路径被文本化并作为使用 RAG 进行 LLM 推理的输入。在GNN-RAG 框架中,GNN 充当密集的子图推理器来提取有用的图信息,而 LLM 则利用其自然语言处理能力进行最终的 KGQA(知识图谱问答)
GNN的训练过程:将知识图谱问答KGQA任务视为节点分类,使用question-answer pairs训练集,将KG entities被分为answers和non-answers,
$ h_v^{(l)}=\psi(h_v^{(l-1)}, \sum_{v’\in N_v}\omega(q,r)\cdo ...
人工智能
未读Graph + RAG图RAG相比于传统RAG的优势:
多跳推理能力 2. 关系建模能力 3. 高效的知识更新与管理 4. 减少检索的噪声和生成的幻觉
最近看了几篇图RAG的论文:
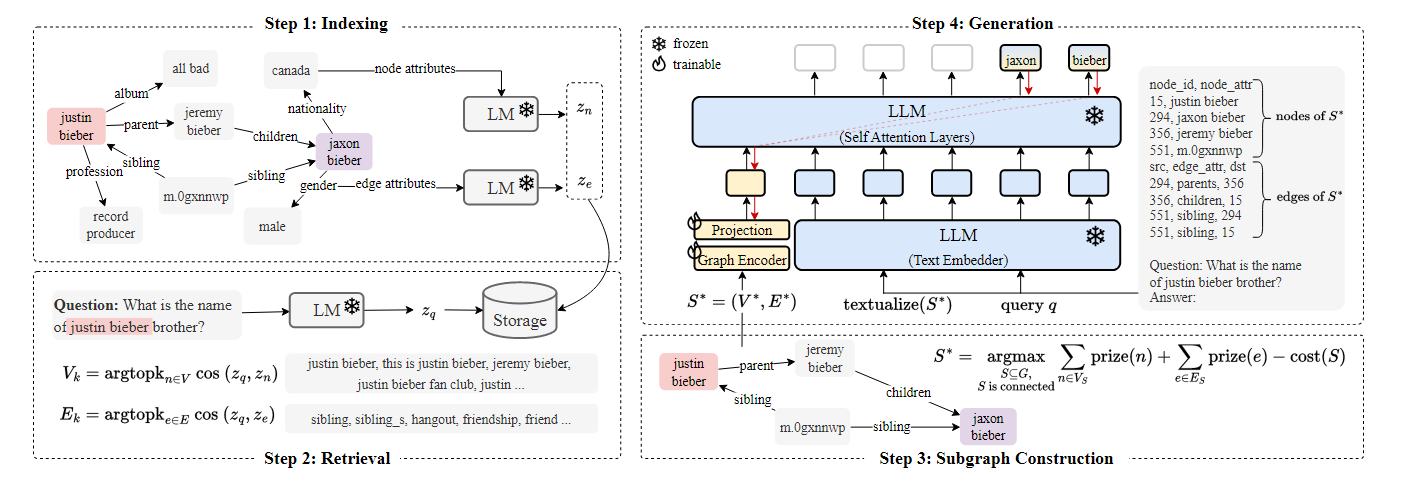
G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering(https://arxiv.org/pdf/2402.07630)Motivation: 引入文本图进行检索增强
开源代码:https://github.com/XiaoxinHe/G-Retriever
首先根据已有的外部知识构建知识图谱,并对每个节点和关系,利用其固有的文本属性进行特征编码。针对用户的query,进行相似度检索,得到节点和边的topk子集。然后设计了一种强化学习策略基于检索得到的子集构建subgraph。在生成阶段,LLM的参数被冻结,除了用户的query以外,还有检索子图的文本属性所构成的hard prompt和基于可训练graph encoder得到的soft prompt
Know ...
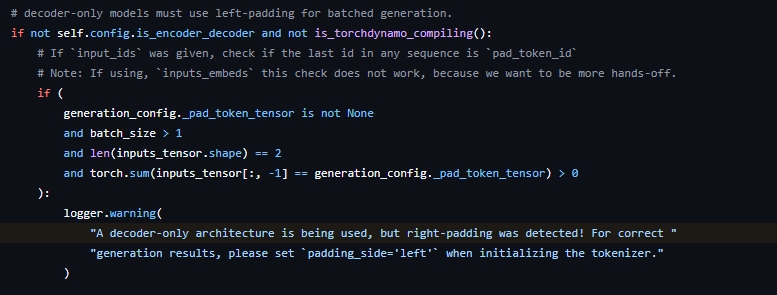
最近微调模型进行原因预测任务训练的时候,在eval阶段进行推理生成时遇到了一个警告:“A decoder-only architecture is being used, but right-padding was detected! For correct generation results, please set padding_side='left' when initializing the tokenizer.”,我将tokenizer初始化的定义设置为左填充依然出现该警告,问了下身边对大模型比较了解的同学,发现是token序列结尾加了eos符号导致出现的warning,下面是transformers库中该警告出现的条件:
为什么模型训练选择右填充,推理时选择左填充;为什么训练时需要在结尾添加标记符,而推理时则不需要,下面给出解释说明:
训练:Q+A[EOS]
模型训练时,对于输入的token序列,我们知道其真实标签(Ques部分可直接用-100作为 mask 填充或无效标签,以确保这些位置不会影响损失计算),采用右填充是为了让每个batch内的样本长 ...

